

Here we go again with you trying to twist something in to something that it isn't because it doesn't agree with you, how is it that you have so much time and energy to straw-man your way through this thread constantly, don't you have anything better to do or is this what you do?
His information came from an article written by Dr Fog https://www.researchgate.net/profile/Agner_Fog a well respected technology analyst. he's quoting it in the video with the data right in front of him.
If you don't like whats in his article go and disagree with him, stop with your constant arguing in this thread.
I'm not trying to twist anything because it doesn't agree with me, I'm stating that what you said doesn't match what AMD themselves have said, it's not me who's twisting or disagreeing with you it's AMD.
I mean seriously this is what's been taken directly from AMD.
And in those documents they state the following...Manuals
- AMD Ryzen CPU Optimization
- AMD Ryzen processors Master Overclocking User Guide
- AMD Financial Analyst Day 2017 - Datacenter
- AMD EPYC
- AMD EPYC 7000-series Product Brief, June 2017
- AMD EPYC Performance Brief, June 2017
- AMD EPYC Solution Brief, June 2017
- AMD x86 Memory Encryption Technologies, David Kaplan, Security Architect, LSS 2016 August 25, 2016
And...Cache
- L0 µOP cache:
- 2,048 µOPs, 8-way set associative
- 32-sets, 8-µOP line size
- Parity protected
And...
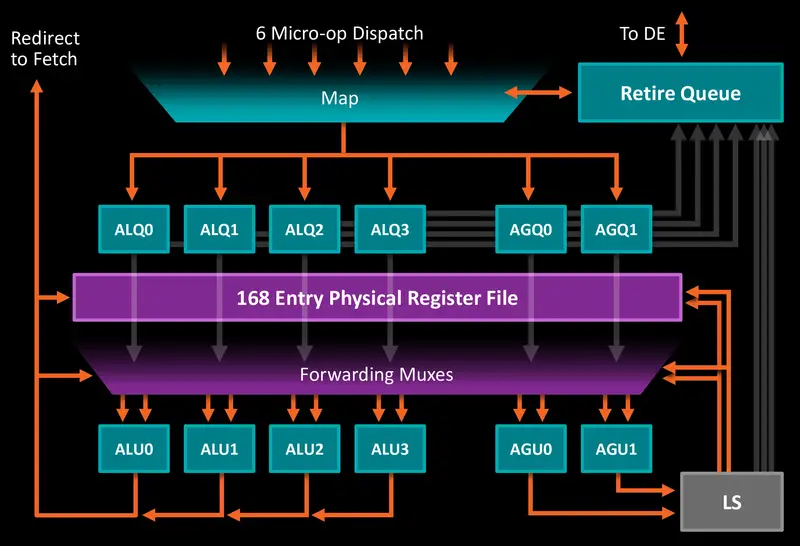
My emphasis to highlight the relevant architecture you mentioned...L1D Cache:
- 32 KiB 8-way set associative
- 64-sets, 64 B line size
- Write-back policy
- 4-5 cycles latency for Int
- 7-8 cycles latency for FP
- SEC-DED ECC
You're literally trying to argue with the people who designed the blooming thing.
And pray-tell what strawman is it that you believe i've constructed? Did you not say "Zen: 2048 uOps, Zen: 10 Integer Execution units, Zen: 4 FP units, Zen: Float latency 3 Cycles"? Did i not say Zen does not have those specific things in the numbers you claimed? Tell me how you think I've misrepresented what you've said.
Also what i do with my time has nothing to do with you, trying to infer some sort of moralistic fallacy serves no purpose and just undermines what you're saying.
Oh and FYI I'm not arguing, i asked you if you was sure the information you posted was correct and suggested it may not be, you then took umbrage when someone attempted to correct your mistake, it's you who is arguing not me, I'm simply trying to refute misinformation.
Oh and one last thing, it would help if you linked to the actual paper that information is taken from and not just the person research gate profile, otherwise how does anyone know what one of his 46 papers the information came from.
") ) published he actually says in the opening introduction, and i quote.
) published he actually says in the opening introduction, and i quote.