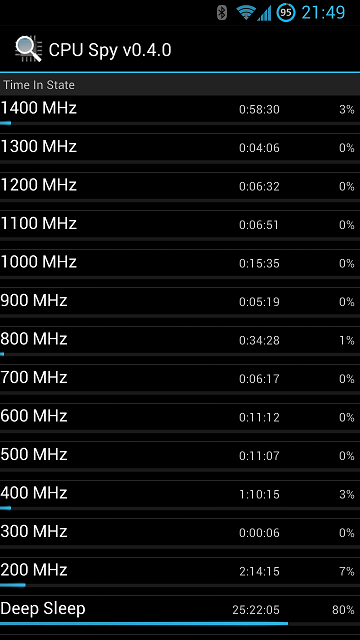
Am I the only one who doesn't get big.LITTLE? I mean, if the A7s are only for low power stuff, why do we need four of them? Unless I'm missing something, what Nvidia's doing with 4+1 seems to make more sense.
big.LITTLE effectively allows 2 different modes of power saving, one is similar to nvidia's solution (but better, imo), the other is ultimately the 'true' implementation of big.LITTLE...
So with nvidia first thing to note is that with the Tegra 3 and, it seems, with the Tegra 4 they've done a more hardware based solution. The 'companion core' is the same architecture as the quad core block, but built with a more power-oriented (rather than speed/performance) lithography process. They then, mostly through hardware, either have all 4 cores running or just the +1 core, this is basically just a bodge because they haven't implemented per-core clock and power gating (where they could just disable 3 cores and have a single one running).
The first implementation of big.LITTLE is similar to the nvidia method but done mostly in software, because of the software bias it's made easier by having the same number of cores in the power hungry side as the efficient side, then the threads/states can be easily transitioned. Note that because Samsung/Qualcomm can actually design decent SoC's it's likely both sets of cores will be power/clock gated per core, so the performance should be able to go from a single A7 at low-ish clock speed to a quad A15 at a high clock speed. But this is only the start of big.LITTLE, by far the easiest to implement but potentially not the most useful as it's one or the other.
So, finally, onto the proper implementation of big.LITTLE, the ability to run different core architectures at the same time. So take a scenario where the system is running with 1 or 2 threads of a game that needs high performance, and many other of the usual threads that are basically idle/unimportant. With the nvidia solution here we'd have 4 full power cores running at the max clock speed sapping battery life. With the current processors and the other big.LITTLE implementation we'd have 3 or 4 high power cores, 2 running maxed out and the other 1 or 2 at whatever speed was necessary, not as bad as nvidia but we can do better. With this implementation we could have 2 A15's running maxed out and then 1 or 2 (or even 3 or 4) A7's running much more efficiently to handle all the unimportant stuff, less heat, less power, better.
The first/easiest implementation of big.LITTLE is managed by software but ultimately can be done with a generic device driver (check power draw/temp/load, swap), relatively easy to plumb into current systems. The hard bit is the better/true implementation of it, namely that to move threads around like that needs the scheduler to have much more knowledge about the system it's running on, this is the bit that is currently unimplemented in the linux kernel last time I checked and even when it does come out will take some tweaking to make full use of the benefits.
For reference, and according to ARM, in some of the theoretical benchmarks the A15 is ~2x the performance of the A7 clock-for-clock, but the A7 is ~3.5x more power efficient. This is one of the reasons why it's quite comfortably superior to the nvidia setup.



 . And I don't really see the point of having 4 A7s either, surely two would be fine?
. And I don't really see the point of having 4 A7s either, surely two would be fine?")

 )
) )
)