could be there could be a f5/bigip product/device to do it, depends on budget restrictions
Budget with as with most of these things for small businesses is unspecified

. They came to me as they wanted a new production server with a mind to put their current, only server, in to use as a spare. In the end they went for a 1K (GBP) 1U unit (E3-1230, 16GB ECC ram, M1015 SAS card, Supermicro server board, case and PSU). Two separate datacentres are to be used for the prod and backup.
They then needed help configuring it and stated having a preference for the data feed to go to both servers with no break in the data and no downtime of service for recovery. It seems they need historical tracking data as part of their service offering.
On discussion of set-up a number of holes were seen and so a couple of questions were put forward for them to think about (testing for patching / new software releases etc, a second server mirroring the fundamental hardware of the first, what if scenarios for them to try to resolve with current infrastructure and the proposed new server).
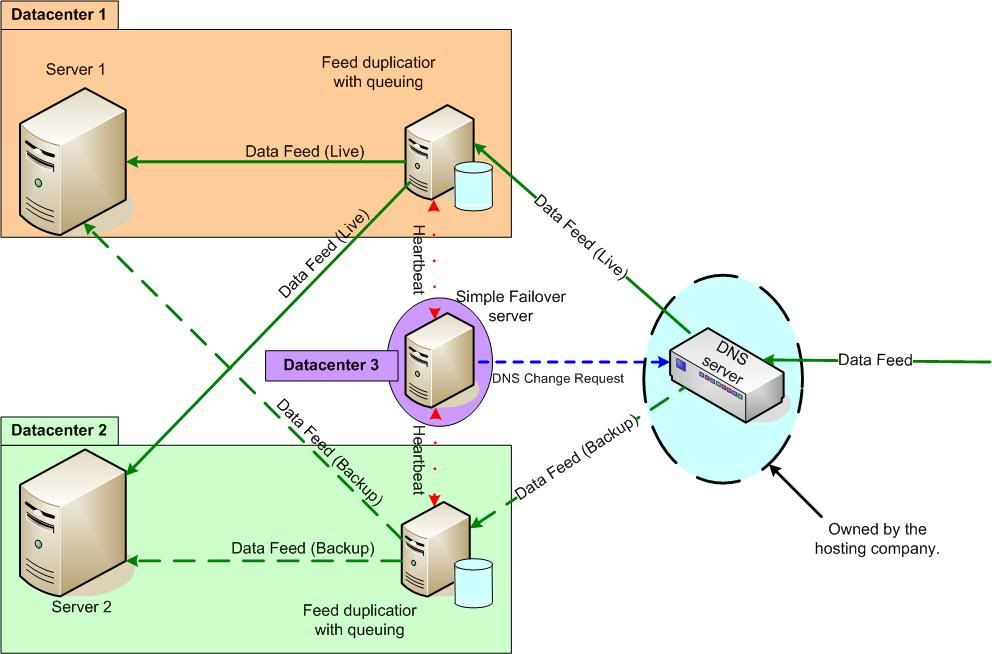
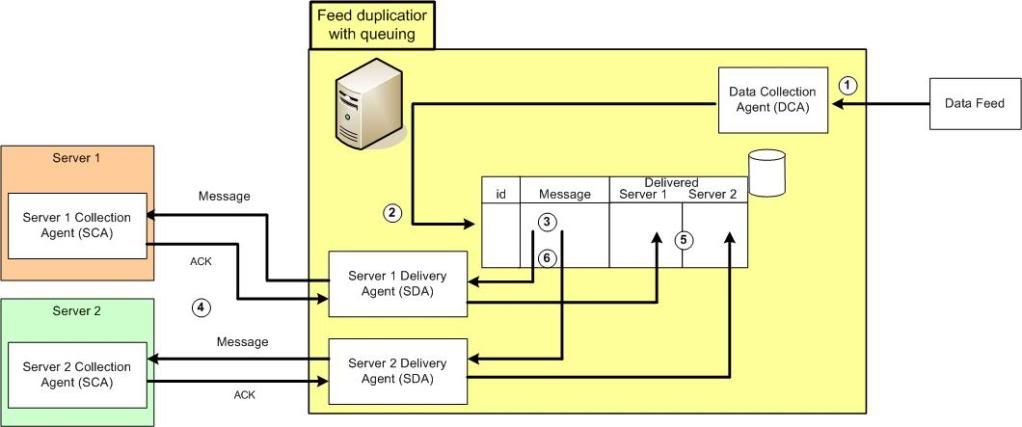
The current proposal is that they replace their backup machine with one to mirror their production server (1/2 memory for now), have a test machine (same Supermicro X9SCM-F-O board as the prod and backup machines with 4GB ECC ram) and have 3 atom D525 based machines to fill the roles of 2xreceive->Queue->Duplicate->Deliver servers and one Simple failover server. It is coming in around 3k (GBP) excluding bespoke software and a simple failover license. The atom units are consumer grade though, jumping to server grade will bump the price up by around S$300 and the servers do not have drives (client is sourcing themselves for the ES SAS drives).
Depends how reliable it must be...the easiest solution would be to use any number of linux tools (I'm 99% sure you can do it with iptables) to duplicate an incoming data stream to multiple end points, then protect that with heartbeat/your choice of linux HA.
You will loose a bit of data during failover though, maybe only a fraction of a second if you configure it well but I can't see it being possible with no loss.
The far more sensible way is to get multiple feeds configured at the source end which will be far easier and more reliable...
Yeah, I had seen the preprocess directive in IPTables which looks good for the duplication but it is the queueing and replay that would seem to be the sticky point. Without the queueing we are back to re-syncing the backend databases with zero downtime.
Currently looking at the following solution for the data feed;
I could also add a hearbeat between Server 1/2 and the Simple Failover Server so they could report if that unit is down.
To be honest, I really do not know if they will want to go for any of this as during the last discussion, one of the clients suggested maintaining the old server as backup but not patching it at all and just having a test server for testing patches to their production system only

.
RB