

-
Competitor rules
Please remember that any mention of competitors, hinting at competitors or offering to provide details of competitors will result in an account suspension. The full rules can be found under the 'Terms and Rules' link in the bottom right corner of your screen. Just don't mention competitors in any way, shape or form and you'll be OK.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
RTX chatbot
- Thread starter Nexus18
- Start date
More options
Thread starter's postsLooks interesting, will definitely check it out later. Did this come out of the blue or had NVIDIA announced they were releasing it?
First I heard/seen of it so seems like out of the blue.
I haven’t looked at it yet but what data are you providing to them? It looks like their main point in the video is it runs locally.You can now use your RTX card to give your data to Nvidia, aren't you happy to pay to become data providers?
I haven’t looked at it yet but what data are you providing to them? It looks like their main point in the video is it runs locally.
Exactly....

RTX AI PCs | Next-Level AI Performance
Unparalleled AI performance in gaming, creativity, and everyday.
www.nvidia.com
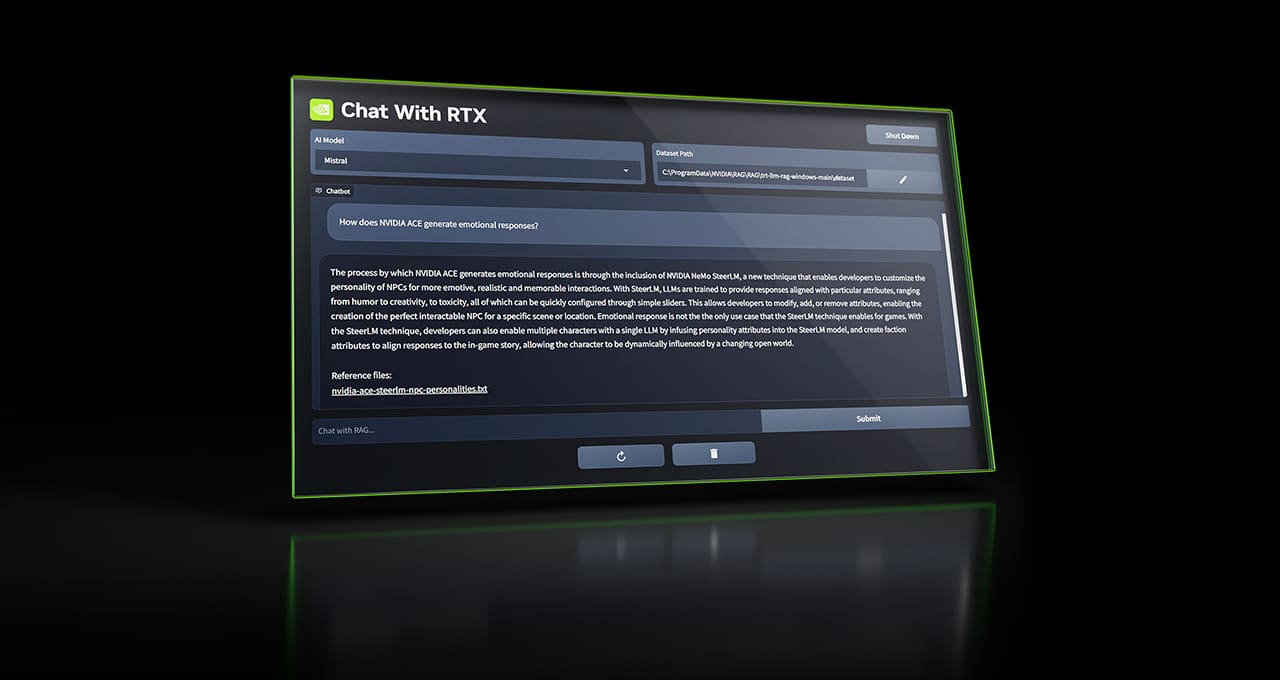
Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs
New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
blogs.nvidia.com
Since Chat with RTX runs locally on Windows RTX PCs and workstations, the provided results are fast — and the user’s data stays on the device. Rather than relying on cloud-based LLM services, Chat with RTX lets users process sensitive data on a local PC without the need to share it with a third party or have an internet connection.
Caporegime
- Joined
- 9 Nov 2009
- Posts
- 25,901
- Location
- Planet Earth
RayTraced eXtreme Chatbot or Raymond the Tenacious eXpansive Chatbot?
Last edited:
Exactly....
RTX AI PCs | Next-Level AI Performance
Unparalleled AI performance in gaming, creativity, and everyday.www.nvidia.com
Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs
New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.blogs.nvidia.com
If it's truely a local app that never ever sends or receives a packet of internet data then it's great, depending on how accurate it can be. Running locally on the GPU it will be much faster than other online models
I may consider using this for work, but will need to make sure it's definitely not using any internet or our I.T team will refuse to let me use it
But also it's usefulness for me will depend on its accuracy of results, from the Nvidia blog I can definitely see how it could speed up work, but only if it's accurate because in my work data errors can lots of money.
Last edited:
What you're seeing here is just a proprietary implementation of open source LLMs, which by their own marketing, are to be used with online accessible material, as without large amounts of data no model is useful.
If you truly think there won't be a metric ton of telemetry embedded then I've got a great deal for a fountain in Rome to sell you...
If you truly think there won't be a metric ton of telemetry embedded then I've got a great deal for a fountain in Rome to sell you...
What you're seeing here is just a proprietary implementation of open source LLMs, which by their own marketing, are to be used with online accessible material, as without large amounts of data no model is useful.
If you truly think there won't be a metric ton of telemetry embedded then I've got a great deal for a fountain in Rome to sell you...
The whole point of this is to keep your data private.... Have you watched the video, read the documents? You have to link/upload the .pdf, .txt etc. to the tool as the source of information in order for it to work. And it works without an internet connection so how can your data be uploaded if there is no internet connection available?
If there is any sign of any your data being fed back, developers will find out and call it out:
GitHub - NVIDIA/trt-llm-rag-windows: A developer reference project for creating Retrieval Augmented Generation (RAG) chatbots on Windows using TensorRT-LLM
A developer reference project for creating Retrieval Augmented Generation (RAG) chatbots on Windows using TensorRT-LLM - NVIDIA/trt-llm-rag-windows
 github.com
github.com
The final install is almost 62GB when all the dependencies are added. It includes Mistral 7B and Llama2 13B LLMs. By default it uses a sample dataset of Nvidia documents, so you get some very biased responses until you either set it to not use this, or feed it your own dataset. It does respond really fast, but it would be nice if they included a larger model for the x090 GPUs.
Here is it's summary of the forum discussion so far:
Here is it's summary of the forum discussion so far:
Based on the context information provided, it seems that the forum discussion is about a new tech demo called "Chat with RTX" that allows users to have a personalized GPT chatbot running locally on their Windows PC with an NVIDIA RTX GPU. The chatbot is powered by a proprietary implementation of open source LLMs, which are intended to be used with online accessible material. The discussion highlights the benefits of using a local app that never sends or receives internet data, as well as the importance of accuracy in the results provided by the chatbot. Additionally, there is a mention of telemetry being embedded in the tool, and the importance of keeping data private.
Last edited:
Soldato
- Joined
- 13 Sep 2010
- Posts
- 2,814
*simping intensifies*Does the chatbot wear a leather jacket?