

I'll PM you details.
And yes, it's one zip per line of data in the csv containing the json file (with the 1 bit of data from csv) and pdf.
It is all done only I don't know what field in the json the directory name is stored under.
I'll PM you details.
And yes, it's one zip per line of data in the csv containing the json file (with the 1 bit of data from csv) and pdf.
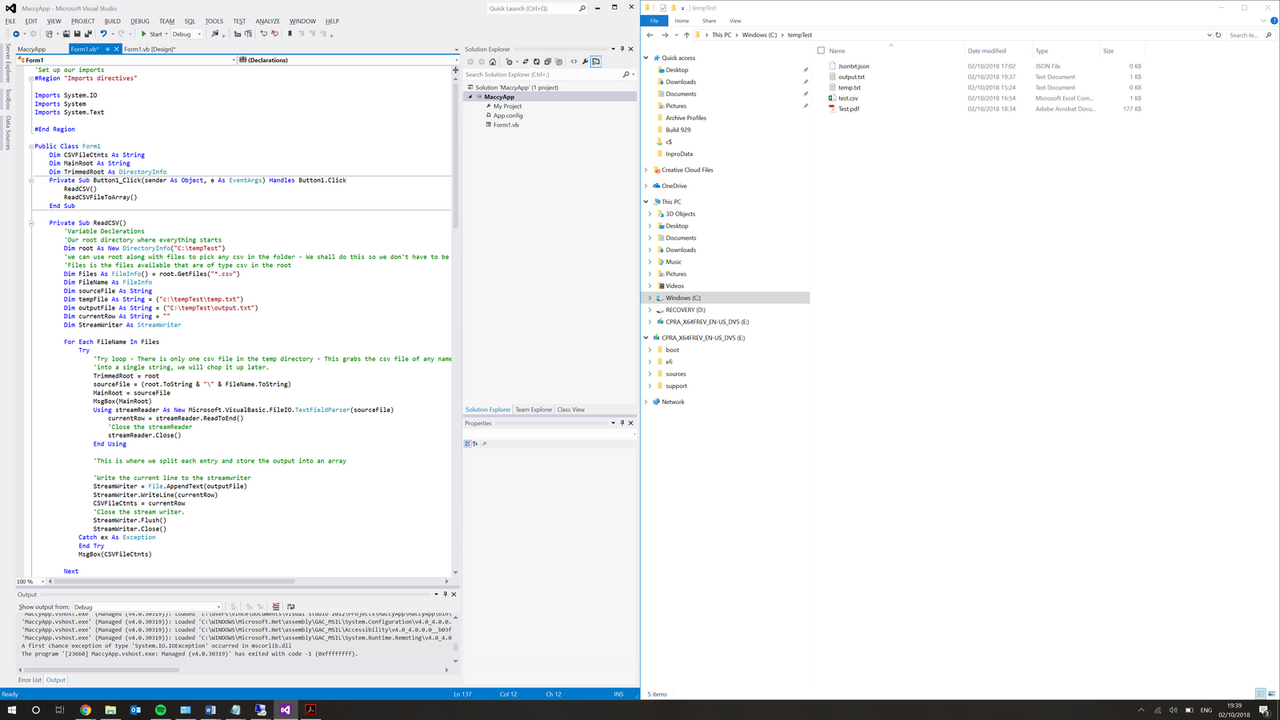
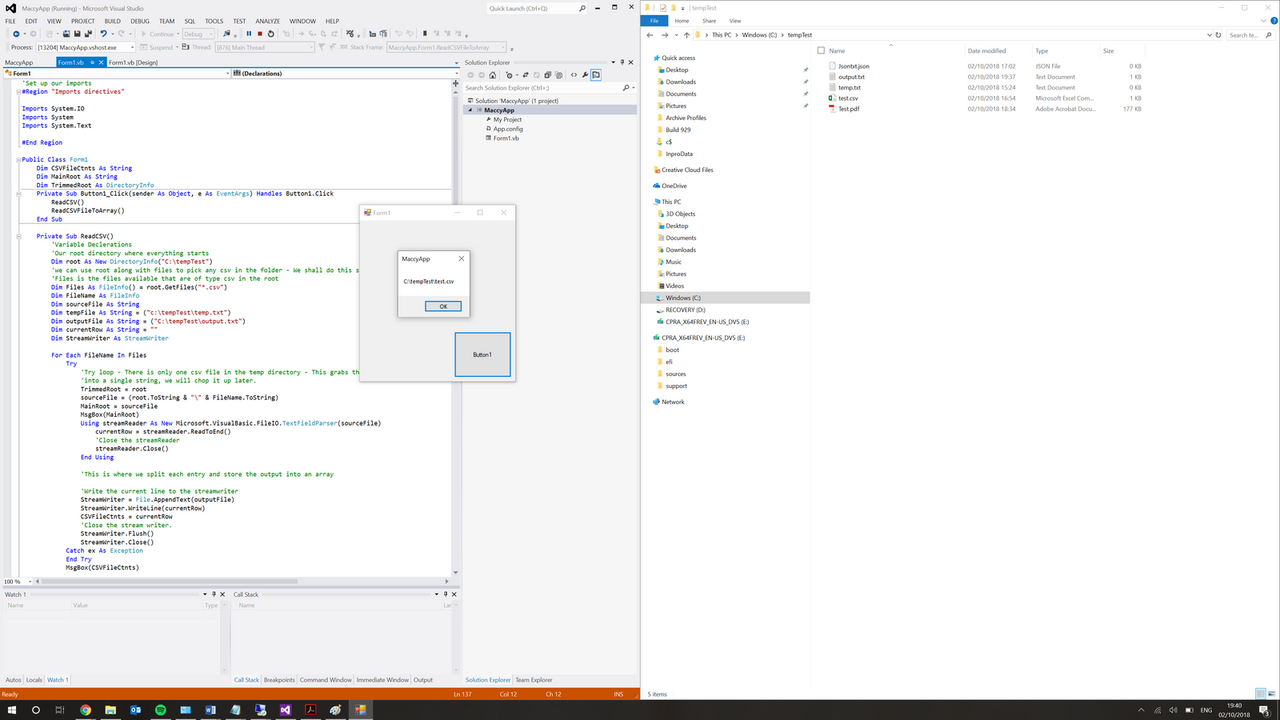
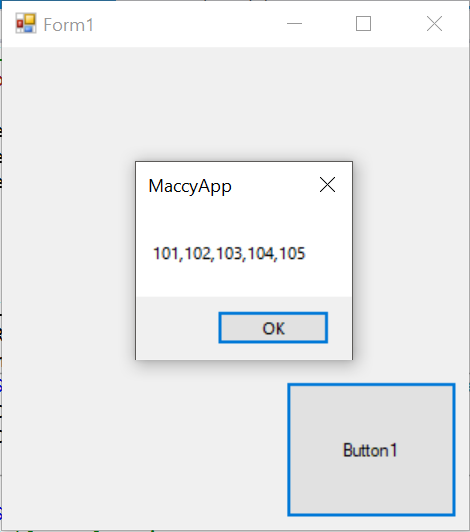
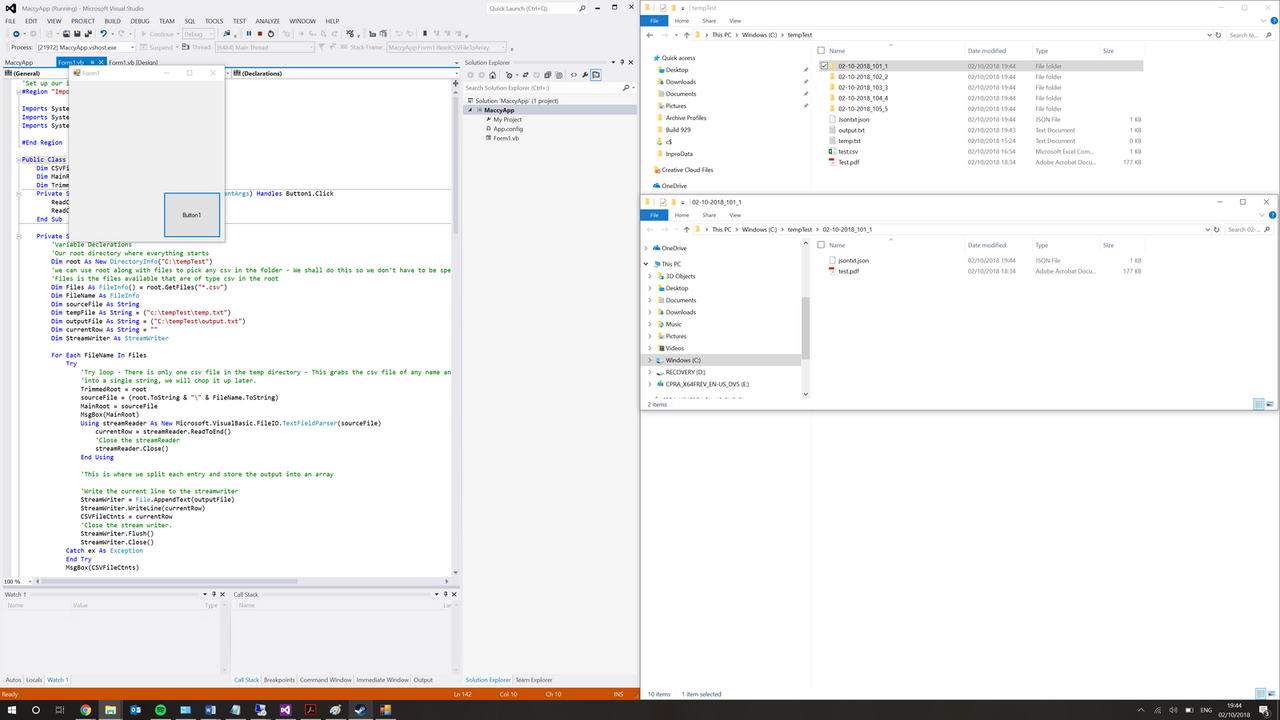
'If I wasn't being so lazy I would have separated each task such copy pdf, update json etc into their own subs so it would have been easier to follow
'Instead we have a sub called ReadCSVFileToArrayAndWork \o/
'Set up our imports
#Region "Imports directives"
Imports System.IO
Imports System
Imports System.Text
#End Region
Public Class Form1
Dim CSVFileCtnts As String
Dim MainRoot As String
Dim TrimmedRoot As DirectoryInfo
Private Sub Button1_Click(sender As Object, e As EventArgs) Handles Button1.Click
ReadCSV()
ReadCSVFileToArrayAndWork()
End Sub
Private Sub ReadCSV()
'Variable Declerations
'Our root directory where everything starts
Dim root As New DirectoryInfo("C:\tempTest")
'we can use root along with files to pick any csv in the folder - We shall do this so we don't have to be specific.
'Files is the files available that are of type csv in the root
Dim Files As FileInfo() = root.GetFiles("*.csv")
Dim FileName As FileInfo
Dim sourceFile As String
Dim tempFile As String = ("c:\tempTest\temp.txt")
Dim outputFile As String = ("C:\tempTest\output.txt")
Dim currentRow As String = ""
Dim StreamWriter As StreamWriter
For Each FileName In Files
Try
'Try loop - There is only one csv file in the temp directory - This grabs the csv file of any name and reads everything
'into a single string, we will chop it up later.
TrimmedRoot = root
sourceFile = (root.ToString & "\" & FileName.ToString)
MainRoot = sourceFile
'debug message box showing our csv file
'MsgBox(MainRoot)
Using streamReader As New Microsoft.VisualBasic.FileIO.TextFieldParser(sourceFile)
currentRow = streamReader.ReadToEnd()
'Dispose of the streamreader
streamReader.Close()
End Using
'Write the current line to the streamwriter
StreamWriter = File.AppendText(outputFile)
StreamWriter.WriteLine(currentRow)
CSVFileCtnts = currentRow
'Close the stream writer.
StreamWriter.Flush()
StreamWriter.Close()
Catch ex As Exception
End Try
'debug
'MsgBox(CSVFileCtnts)
Next
End Sub
Private Sub ReadCSVFileToArrayAndWork()
Dim strfilename As String
Dim num_rows As Long
Dim num_cols As Long
Dim x As Integer
Dim y As Integer
Dim strarray(1, 1) As String
Dim jsontxt As String
Dim caseNo As String
Dim PDFName As String = "test.pdf"
Dim PDFLoc As String
Dim CaseDirPDF As String
Dim StreamWriter As StreamWriter
Dim DirectoryName As String
Dim jsonLoc As String
Dim jsonSource As String = ("C:\tempTest\jsonSource.json")
Dim jsonOut As String = ("C:\tempTest\jsontxt.json")
Dim jsonFile As String = "jsontxt.json"
Dim CaseDirJson As String
' Load the file location
strfilename = MainRoot
'Check if file exist
If File.Exists(strfilename) Then
'more declarations
Dim tmpstream As StreamReader = File.OpenText(strfilename)
Dim strlines() As String
Dim strline() As String
Dim TDate As DateTime = Now
Dim increment As New Integer
'Load content of file to strLines array
strlines = tmpstream.ReadToEnd().Split(Environment.NewLine)
'Redimension the array
num_rows = UBound(strlines)
strline = strlines(0).Split(",")
num_cols = UBound(strline)
ReDim strarray(num_rows, num_cols)
'loop through and copy the data into the array.
For x = 0 To num_rows
strline = strlines(x).Split(",")
For y = 0 To num_cols
strarray(x, y) = strline(y)
Next
Next
'set our number to increment before the loop
increment = 0
'Begin looping through our array and creating everything
For x = 0 To num_rows
For y = 0 To num_cols
increment = increment + 1
'Location of the PDF to copy
PDFLoc = (TrimmedRoot.ToString & "\" & PDFName)
'Make a directory
MkDir(TrimmedRoot.ToString & "\" & (TDate.ToString("dd-MM-yyyy")) & "_" & (strarray(x, y) & "_" & increment))
DirectoryName = (TrimmedRoot.ToString & "\" & (TDate.ToString("dd-MM-yyyy")) & "_" & (strarray(x, y) & "_" & increment))
'Set Location of where the PDF is being stored
CaseDirPDF = (TrimmedRoot.ToString & "\" & (TDate.ToString("dd-MM-yyyy")) & "_" & (strarray(x, y) & "_" & increment & "\" & PDFName))
'Copy the PDF
My.Computer.FileSystem.CopyFile(PDFLoc, CaseDirPDF)
'copy out the case number to a variable
caseNo = strarray(x, y).ToString
'debug msgbox
'MsgBox("case number is: " & caseNo)
'Create our new line of json
jsontxt = (ControlChars.Quote & "case_number" & ControlChars.Quote & ":" & " " & ControlChars.Quote & caseNo & ControlChars.Quote & ",")
'debug msgbox
'MsgBox("json line is: " & jsontxt)
'Create a stream reader to read the json file to find the line we are replacing
Dim jsonFileNew As New StreamReader(jsonSource)
Dim jsonLine As String ' holds one line at a time
Dim jsonLines As String 'holds the whole file
Dim posOf_txt As Integer 'For our txt compare
jsonLine = jsonFileNew.ReadLine
jsonLines = jsonLine
'loop through all lines of json
While Not jsonLine = ""
jsonLine = jsonFileNew.ReadLine
posOf_txt = InStr(1, jsonLine, "case_number", vbTextCompare)
If posOf_txt > 1 Then
jsonLines = jsonLines & vbCrLf & jsontxt
jsonLines = jsonLines & vbCrLf & ControlChars.Quote & "directory_name" & ControlChars.Quote & ":" & " " & ControlChars.Quote & DirectoryName & ControlChars.Quote & ","
ElseIf posOf_txt = 0 Then
jsonLines = jsonLines & vbCrLf & jsonLine
End If
End While
'debug
'MsgBox(jsonLines)
StreamWriter = File.AppendText(jsonOut)
StreamWriter.WriteLine(jsonLines)
'Dispose of the streamwriter
StreamWriter.Flush()
StreamWriter.Close()
jsonLoc = ((TrimmedRoot.ToString & "\" & jsonFile))
CaseDirJson = (TrimmedRoot.ToString & "\" & (TDate.ToString("dd-MM-yyyy")) & "_" & (strarray(x, y) & "_" & increment & "\" & jsonFile))
My.Computer.FileSystem.CopyFile(jsonLoc, CaseDirJson)
My.Computer.FileSystem.DeleteFile(jsonOut)
Next
Next
End If
End Sub
End Class#---- DECLARE VARIABLES HERE ----#
workingDir=/location/of/your/working/directory/
zipLocation=/location/of/your/working/directory/zip_files/
pdfFile=1111001.pdf
pdfLocation=/location/of/your/pdf/file/
csvFile=converted-CSV-file.csv
#---- END OF VARIABLE DECLARATION ----#
#create a unique int that increments through each loop
var=1
while IFS=, read -r f1
do
#cd to the working directory
cd "$workingDir"
#print the case number from each row
echo "The case number from the CSV is $f1 that we are using"
#create the unique folder name using the looped var and required folder structure name
case=${f1}
folder="_24-06-2018-00-00-00"
caseFolder=$var$folder
#create the directory for each zip file using mkdir
mkdir "${caseFolder}"
echo "Created dir with name $caseFolder"
#cd into the new directory
cd "${caseFolder}"
#create the metadata.json file with the required content (template and case number var)
cat >./metadata.json <<EOF
{
"case_number": "${case}",
"rest of json":"goes here"
}
EOF
#copy the required PDF file into the new dir
cp ${pdfLocation}${pdfFile} ${pdfFile}
#move back up a dir
cd ..
#zip the folder
zip -r ${caseFolder}.zip ${caseFolder}
#move the zip file to a separate folder to collate all data in one location
mv ${caseFolder}.zip "${zipLocation}"
#increase the value of i
var=$((var+1))
done < ${csvFile}Afraid not, line break is still present.case=$(printf $f1)
Try that mate... see if it works
Stelly
##===========================================##
# IMPORTS
import glob
import os
import time
import datetime
import json
import csv
import shutil
##===========================================##
# Find the csv file in the parent folder
main_csv = glob.glob('*.csv')
main_csv = main_csv[0]
template_pdf = glob.glob('*.pdf')
template_pdf = template_pdf[0]
template_json = glob.glob('*.json')
template_json = template_json[0]
##===========================================##
# Create the new unique directory for each entry in the csv
path = os.getcwd() #get the parent directory
time_dir = time.time()
time_dir = datetime.datetime.fromtimestamp(time_dir).strftime('%d-%m-%Y-%H-%M-%S')
unique_int = 0
with open (main_csv) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
new_dir = str(unique_int) + "-" + time_dir #sets the directory name of a unique integer and the current date time
os.mkdir(new_dir) #creates the unique directory
shutil.copy2(template_pdf, new_dir+'/template.pdf') #copies the pdf file into the directtory and names it "template.pdf"
shutil.copy2(template_json, new_dir+'/template.json') #copies the json file into the directtory and names it "template.json"
#Now I need to open the json file, edit it and save in the new directory
#zip the folder up
shutil.make_archive(new_dir, 'zip', new_dir)
#increase unique integer at the beginning of the folder name
unique_int = unique_int + 1
##===========================================##Jesus that esculated into .Net nonesense quickly.
Lets see:
Then it's not a CSV file. It's just a list.
- Read a CSV file containing a few thousand rows of data (only one column)
for row in $(cat theFile)
do
done
If you just want it to be unique and nothing else you can use "mktemp", if you want the date in that format use the date command and the +% format specifiers, then assign to a variable something like:
- Create a directory with a unique name (in the format X_DD-MM-YYYY_HH-MM-SS) eg. 1_24-06-2018-00-00-01 - hoping I can increment the time value to make the dir unique?
theDate=$(date +%d%M%y_%hh%mm%ss)
If you just want it to be a unique item based on the date the easiest is:
date +%s
Unix epoc.
However I expect you just want to increment the first number.
i=1
i=$(( $i++ ))
theDirectory=${i}_${theDate}
Already done with the for loop above, "row" is your variable
- Grab the value from the CSV and store it as a variable
Create a template JSON file.
- Create a .json file with the above variable used once in one of the json fields and the directory name in one of the json fields
Make the variables placeholders like [[VAR1]] [[VAR2]]
cat the JSON file and pipe through sed
cat theJson.template.json | sed "s/[[VAR1]]/$thevalue/" | sed "s/[[VAR2]]/$theothervalue/" > $theDirectory/${thefile}.json
Already done in above step
- Save the .json file in the above dir
cp thePDF.pdf $theDirectory
- Copy a PDF file from another dir (I should be able to do this using the 'cp' function)
zip ${theDirectory}.zip ${theDirectory}
- Zip up the new folder with the .json file and the PDF fil
Meh.. nonsense perhaps but then it's been years since I've written anything in any shell / bash. I'll get my coat.
#---- DECLARE VARIABLES HERE ----#
workingDir=/my/working/dir/
zipLocation=/my/working/dir/zip_files/
pdfFile=pdf_file.pdf
pdfLocation=/location/of/pdf/
csvFile=file.csv
jurisdiction=someData
#---- END OF VARIABLE DECLARATION ----#
#create a unique int that increments through each loop
var=1
while IFS=, read -r f1
do
#cd to the working directory
cd "$workingDir"
#print the case number from each row
#echo "The case number from the CSV is ${f1} that we are using"
#create the unique folder name using the looped var and required folder structure name
#case=$(printf ${f1})
case="$(echo "$f1"|tr -d '\r')"
folder="_24-06-2018-00-00-00"
caseFolder=$var$folder
#create the directory for each zip file using mkdir
mkdir "${caseFolder}"
echo "Created dir with name $caseFolder"
#cd into the new directory
cd "${caseFolder}"
#create the metadata.json file with the required content (template and case number var)
cat >./metadata.json <<EOF
{
"case_number": "${case}",
"jurisdiction": "${jurisdiction}",
"zip_file_name": "${caseFolder}.zip",
****REST OF JSON GOES HERE, DELETED INTENTIONALLY****
}
EOF
#copy the required PDF file into the new dir
cp ${pdfLocation}${pdfFile} ${pdfFile}
#move back up a dir
cd ..
#zip the folder
zip -r ${caseFolder}.zip ${caseFolder}
#move the zip file to a separate folder to collate all data in one location
mv ${caseFolder}.zip "${zipLocation}"
#remove the zip folder we created earlier as we no longer require them
rm -rf ${caseFolder}
#increase the value of i
var=$((var+1))
done < ${csvFile}