

Soldato
- Joined
- 14 Aug 2018
- Posts
- 3,939
This one here.The 9700K? what Screenshot? the only one you posted was for the 3900X.
https://forums.overclockers.co.uk/posts/33216659/
Please remember that any mention of competitors, hinting at competitors or offering to provide details of competitors will result in an account suspension. The full rules can be found under the 'Terms and Rules' link in the bottom right corner of your screen. Just don't mention competitors in any way, shape or form and you'll be OK.
This one here.The 9700K? what Screenshot? the only one you posted was for the 3900X.
@humbug the increase in performance of your over 4.0GHZ Ryzen 5 3600 over my 3.6GHZ Ryzen 5 2600 is not as big as I expected - so I am at 27 seconds,and you are at 23~24 seconds,so its almost like its the clockspeed difference accounting for the performance jump in your case.
Edit!!
I will badger my mate with an overclocked Ryzen 7 2700 to see if he can run the test too,although his RAM is only running at 3000MHZ IIRC.
You're right it is... 23 vs 27 is a fraction under 18% faster, 3.65Ghz vs 4.075Ghz, to get from 3.65Ghz to 4.075Ghz you need just shy of 12% higher clocks, so that that leaves just 6%.
Its closer to 3.6GHZ with SMT on,so something seems a bit off IMHO - it seems to be using SMT fine on my Ryzen 5 2600,and like I said there is a slight performance boost keeping it enabled.
Edit!!
Humbug,try running the software with SMT switched off and see what results you get.
")
Thanks for doing that!
If anybody else wants to then this is how to apply the preset:
 finally justification for TR3
finally justification for TR3 
Actually it should be more like 10.5% to 15.7% not 12% - 18% so this would make it a ~5% improvement. At 5.3Ghz it does it most times in 16secs but because the in-built timer doesn't give decimals this could be 16.3secs rounded down whereas at 5.2Ghz it could be 16.8sec rounded up to 17secs. So then there's even less % improvement between the two.How are you get another 6% more with a 100MHZ clockspeed increase? Something is not right there!
But,this really puts things in perspective for me - I have a SFF PC, so it appears at stock any of these Intel CPUs won't actually be really quicker even if you are applying filters.
It's just my own narrow anecdotal experience but this was done with a real-time, very high quality video capture. When I had HT enabled on a Xeon system then I would get dropped frame. Once I disabled HT then zero dropped frames.Got any decent benchmarks for that? I've never found proper testing online. (You can find results for individual CPUs but not good comparisons side by side in equal circumstances over a broad range of application).
I've not tested it in awhile but when I did I found that AMD's SMT typically had a bigger penalty for enabling it which makes it look like the gains are bigger but really aren't. AMD's implementation tended to do better in synthetic tests and situations that were highly multi-threaded (probably due to the way they utilise the integer units) but worse in general applications and situations with more mixed workload demands - overall results were largely about the same.
It's just my own narrow anecdotal experience but this was done with a real-time, very high quality video capture. When I had HT enabled on a Xeon system then I would get dropped frame. Once I disabled HT then zero dropped frames.
With the Ryzen 3900X even leaving SMT enabled I did not get any dropped frames, though interestingly when if was combined with slower untuned RAM that is when I got dropped frames.
Actually it should be more like 10.5% to 15.7% not 12% - 18% so this would make it a ~5% improvement. At 5.3Ghz it does it most times in 16secs but because the in built timer doesn't give decimals this could be 16.3secs rounded down whereas at 5.2Ghz it would be 16.8sec rounded up to 17secs. So then there's even less % improvement between the two.
Yes as you are discovering that you can also do batch exports which will fully load up all cores. There's a setting in preferences for Maximum Number of Simultaneously Processed Images. The default recommended amount is 2 but it can go as high as 8.@humbug I made a few identical copies of the file and did a quick 5 image batch conversion using the same presets.

It takes 120 seconds for 5 images,which is 24 seconds per image. I tried it with 8 images,and it took around 184 seconds which is 23 seconds per image.

There is far better thread utilisation happening too.

My mate decided to run the same conversion on his system,which is an overclocked Ryzen 7 2700 running at 4GHZ with 3400MHZ DDR4 and NVME SSDs.
Their single image time is 25 seconds,with 5 images it took 91 seconds,around 18.2 seconds per image,they then tried 8 images,and took 132 seconds,or 16.5 seconds per image and with 64 images,it took 16.2 seconds.
With DxO its better to batch a few images together as it actually processes images much more efficiently. You can see that as it actually processes two images at any one time.
Thanks for clarifying it!
You could well be correct though I find it more so for occasions where you can't guarantee that all cores will be maxed out all the time and then the scheduler is employed in 'choosing' cores to utilise.Sounds like the software just doesn't like HT - back in the day with the Pentium 4 HT era a small number of games would stutter with HT enabled. Dunno what OS that was on but you might find it related to core parking as well - on some of my systems on Windows 7 I have to do the core parking tweak on CPUs with HT or it stutters in Battlefield games.
I was going to send you a message asking you to run the test so I'm glad you did it. Yours is the fastest thus far I believe.nm figured it out. first run 9900k 5.2ghz. 15 seconds:
I was going to send you a message asking you to run the test so I'm glad you did it. Yours is the fastest thus far I believe.
@humbug I made a few identical copies of the file and did a quick 5 image batch conversion using the same presets.

It takes 120 seconds for 5 images,which is 24 seconds per image. I tried it with 8 images,and it took around 184 seconds which is 23 seconds per image.

There is far better thread utilisation happening too.

My mate decided to run the same conversion on his system,which is an overclocked Ryzen 7 2700 running at 4GHZ with 3400MHZ DDR4 and NVME SSDs.
Their single image time is 25 seconds,with 5 images it took 91 seconds,around 18.2 seconds per image,they then tried 8 images,and took 132 seconds,or 16.5 seconds per image and with 64 images,it took 16.2 seconds.
With DxO its better to batch a few images together as it actually processes images much more efficiently. You can see that as it actually processes two images at any one time.
Thanks for clarifying it!
which is also compatible for all the plugins and bridges i need for 3D texturing stuff.....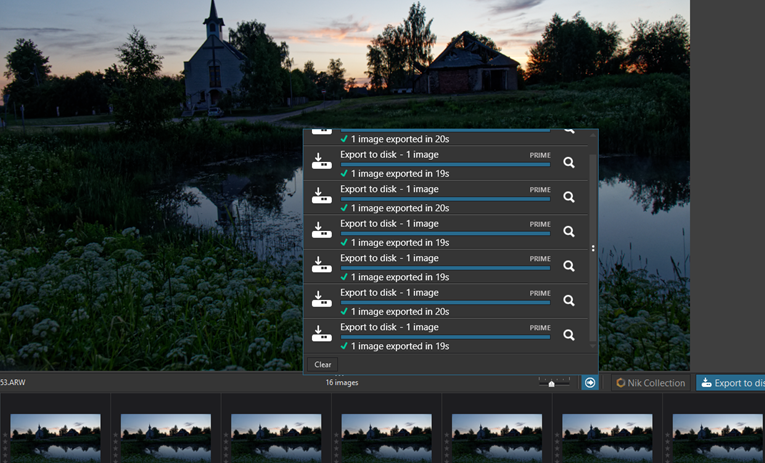
Yes as you are discovering that you can also do batch exports which will fully load up all cores. There's a setting in preferences for Maximum Number of Simultaneously Processed Images. The default recommended amount is 2 but it can go as high as 8.
If you have a lot of images that all have the same adjustments then you can do it this way that will max out all cores. In this scenario multicore machines would come into their own. Historically though you'd find the odd one would fail in an error so I don't know if they've fixed that.
This way doesn't really work for me though because I generally have slight adjustments that I make to each photo so have to do them singularly.
Actually yes you're right. I remember doing that on my Xeon 24 core system, though to get the cores to load up I had to select at least 6 simultaneously. The problem was that quite a few would error and then it became a chore to go and find which ones and then redo them, which in turn would offset the export into Lightroom which just meant more work for me in the end.You can batch with individual adjustments per picture - that is what I have done when processing pictures I took for a friend.
")
