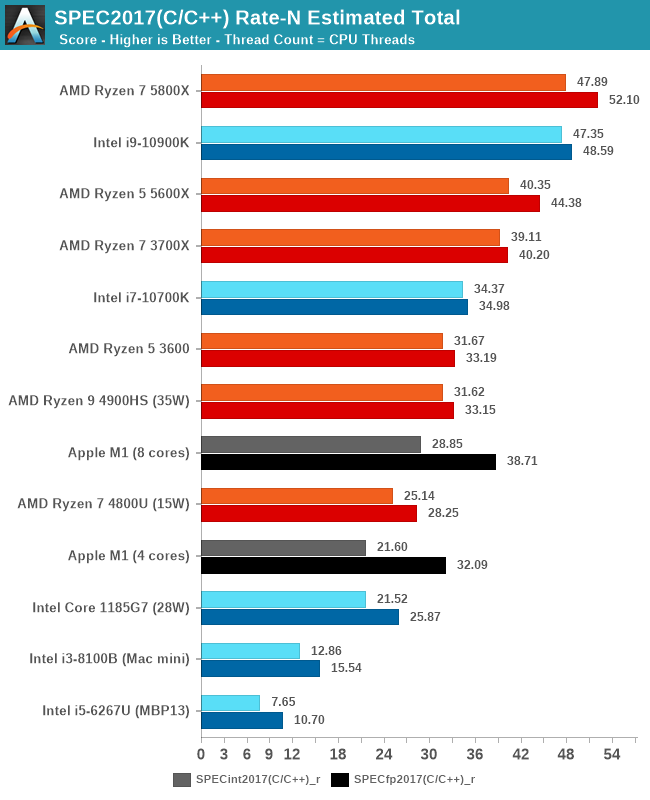
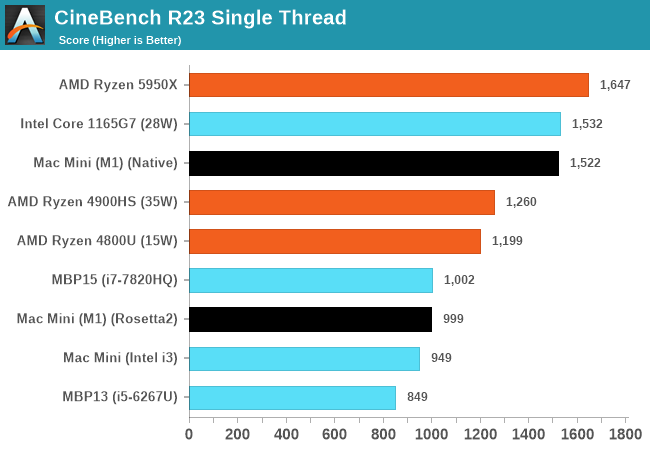
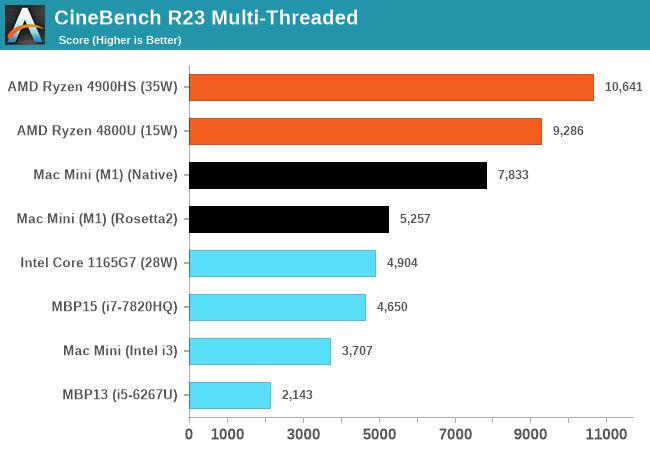
That's because Cinebench R23 is literally designed to scale as close to linearly as possible. There are embarrassingly parallel tasks that do (rendering, text compression, etc). That same Cinebench R23 task will also scale linearly with non-x86 architectures. You can compare those un SPEC subbenchmarks in the Anandtech review.
Give or take a few instructions, those server-grade CPUs use exactly the same ISA as every other ARM chip, and that's also the same for x86 (laptop/desktop/server use the same ISA). What they show is that the claims that ARM architecture can't scale (or can't compete on performance) isn't true. If the focus becomes scaling or performance, they can compete.
The same is also true of x86 and efficiency, they can compete on efficiency. There's not much in the x86 ISA that prohibits that.
It will be close enough to that in tasks where it's supposed to be, you can see Cinebench R23 on M1, multi-threaded score is 5x the single threaded one, which is what you'd expect (each small core is about 20% of the performance of big core). Adding more in an embarrassingly parallel task will just scale.
Multicore scaling (up to about 200 cores) was solved more than a decade ago and all architectures use roughly the same principles and achieve similar results.
You shouldn't compare a 4+4 core to an 8-core CPU. The 4 efficiency cores are not there for performance (performance is ~20% of big cores), they're there for handling background tasks. Intel is also moving to Big.Little in the future, so we'll see this sort of thing more often. The reason Intel and AMD don't use it already because Windows doesn't take advantage of heterogenous CPUs so little point for Intel and AMD to implement it but Windows will support it soon.
Here you can see comparison of 4-core M1 versus 8-core M1, the 4 small cores only add as 20%.
Also M1's multithreaded are ~5x of the single threaded one, very close to what you'd expect from 4 fast cores and 4 cores that are 20% as fast. Each core itself is competitive with Zen 3 cores.