- Joined
- 5 Aug 2018
- Posts
- 132
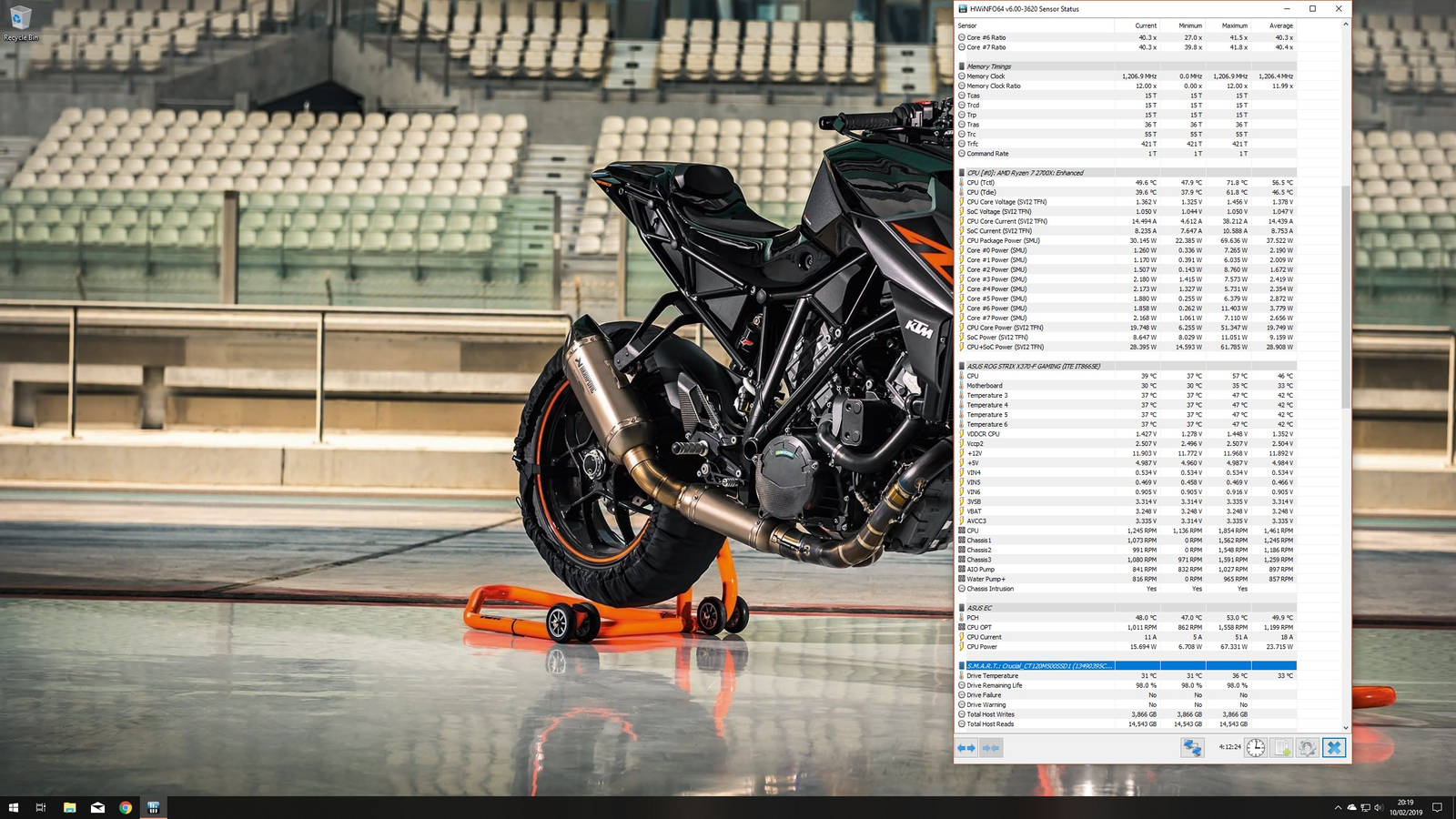
So the rig has been up and running all evening on the 670 now with no hard crash so the aorus 1080ti is not out of the woods yet. Going to leave it on just on the desktop over night as at the moment it seems the hard crash could well be down to the gpu as the temp anomalies never seemed to directly cause the hard crash (during this evening I have seen 5 temp anomalies).
If it's still running by morning that will be the longest I've ever been able to have it running without hard crash which could indicate the two issues were never actually connected. If that's the case I may need to get OCUK to RMA the GPU and whichever component I can narrow the temp anomalies down to.
So for now the RAM / PSU / Case testing will have to wait till morning.
If it's still running by morning that will be the longest I've ever been able to have it running without hard crash which could indicate the two issues were never actually connected. If that's the case I may need to get OCUK to RMA the GPU and whichever component I can narrow the temp anomalies down to.
So for now the RAM / PSU / Case testing will have to wait till morning.